Projects and interests
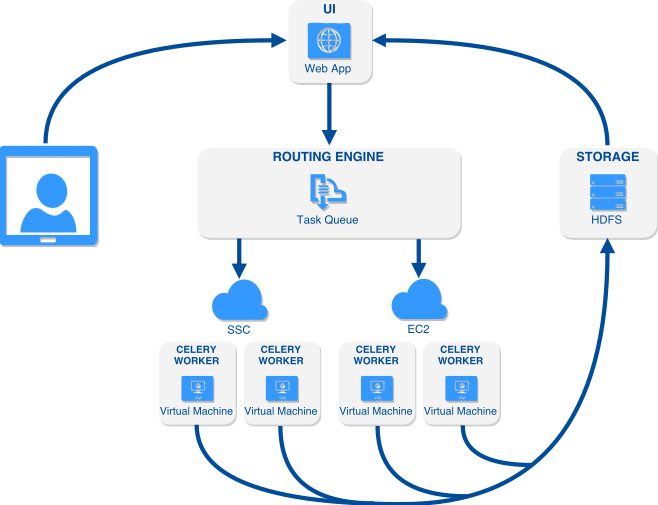
AI home assistant
We've been experimenting at home with building a little agentic, LangGraph-based AI assistant to help manage everyday stuff — like calendars, shopping lists, meal planning, and notes. It connects tools like Notion, Google Calendar, and Google Sheets, and is easy to customize with new features.
GitHub
Loppiskartan.se
Doing some data stuff for Loppiskartan.se, a website that collects second hand stores and flea markets across Sweden.

Rethinking detection of money laundering
In this project, we explored a few different approaches that can help improve the detection and prevention of money laundering: leveraging graph-based ML methods, using federated learning to allow collaboration without actually sharing data, and ways to create realistic simulated data to allow for benchmarking and improved method-development.
See the paper on arXiv .
GitHub

Interactive data visualization
I experimented with using Bokeh for interactive visualizations that require more customization, while keeping everything purely Pythonic. It’s flexible, relatively fast, and works well in both web apps and notebooks.
I found it particularly helpful for exploring large, complex datasets in the following projects:
GitHub
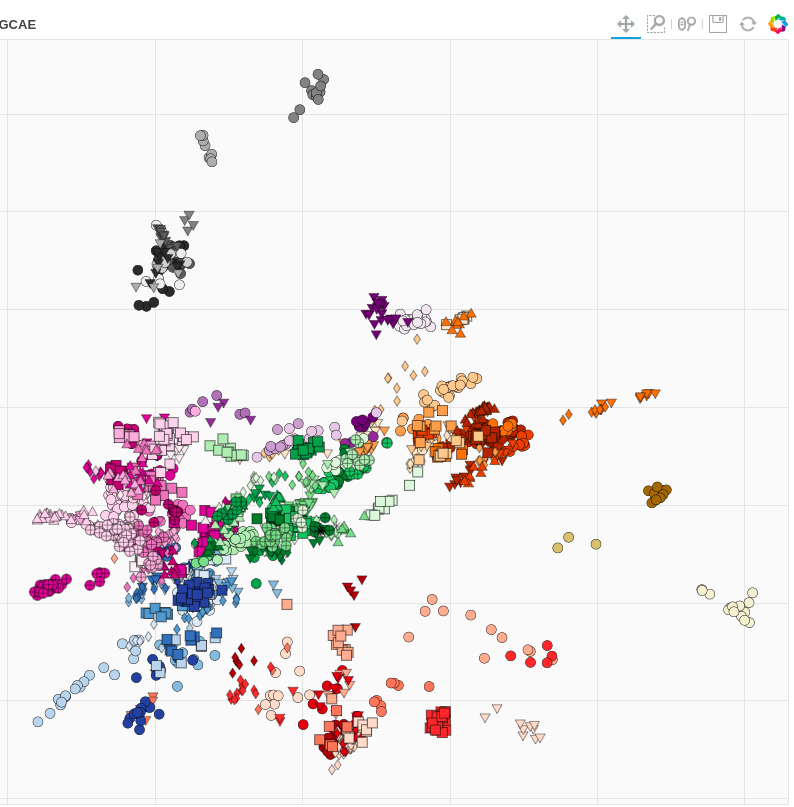
Exploring human population structure
Its pretty cool that if we reduce the whole genome of humans down to just two values and plot them, then we get a (kind of) map of the Earth.
View Visualization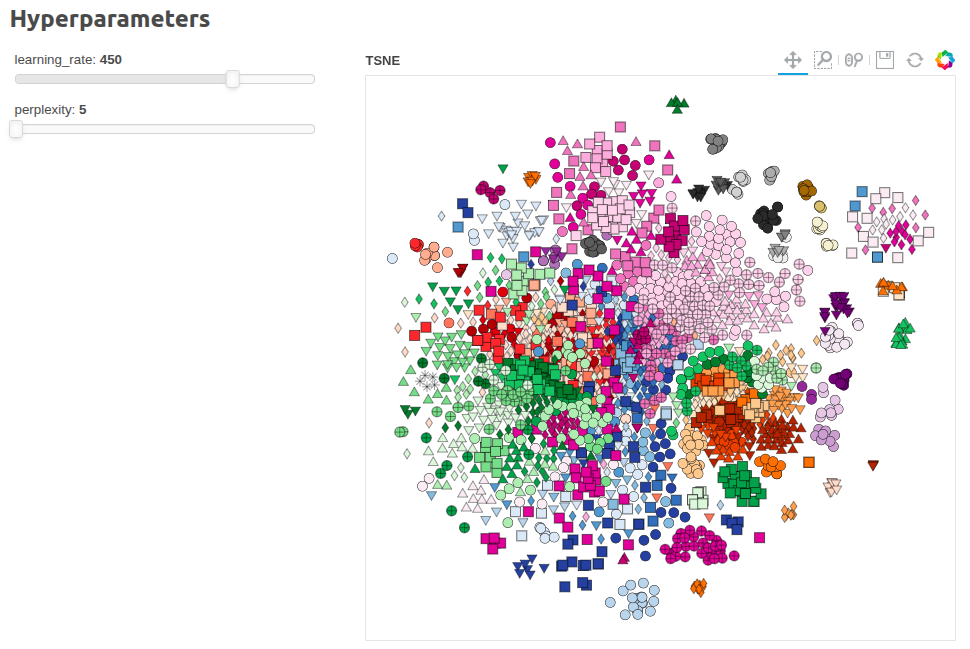
Hyperparameter Tuning of t-SNE, UMAP, ISOMAP
How do the hyperparameters affect the results when you use t-SNE, UMAP and ISOMAP for dimensionality reduction.
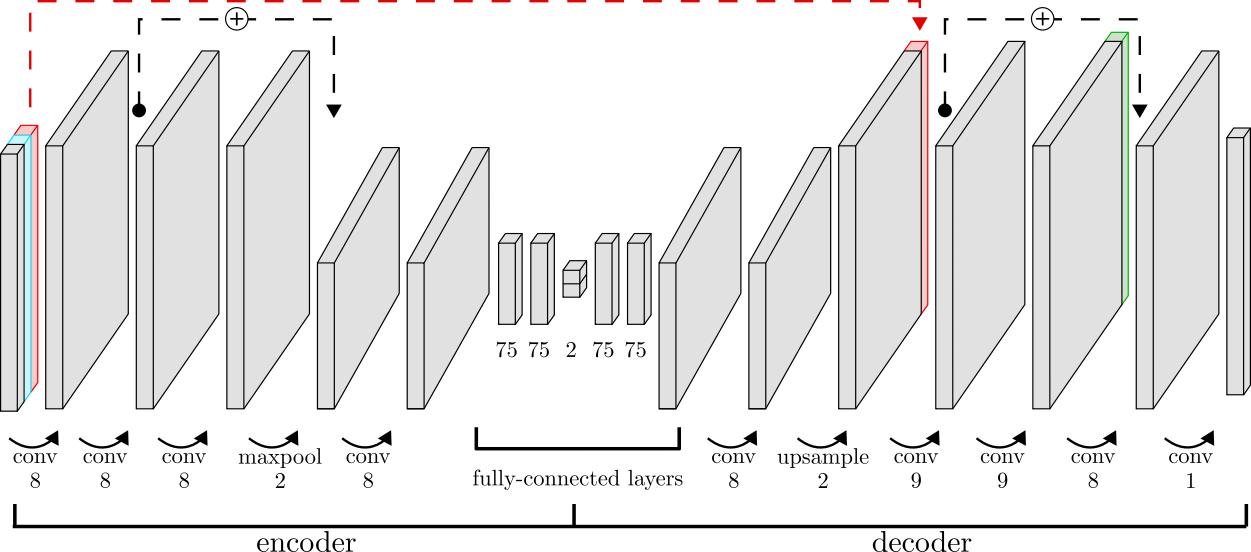
View VisualizationDeep learning for genetic data
A deep-learning framework based on convolutional autoencoders for use on genetic data that I developed during my PhD. This paper describes the model and how it can be used for dimensionality reduction as well as genetic clustering. We show how this nonlinear, data-driven approach can learn a useful representation of complex genetic data sets, and provide new insights in comparison to traditional methods.
Here's an interactive version of the dimensionality reduction results presented in the paper.
GitHub
Serverless workflow execution engine
A collaboration with researchers at the University of Washington, Seattle, the Serverless Workflow Enablement and Execution Platform (SWEEP) is a workflow management system based on the serverless paradigm. The goal of SWEEP is to simplify the creation of cloud-native workflows, allowing users to define tasks as functions or containers, set up rules regarding their orchestration, and execute them in the cloud without setting up any virtual infrastructure.
Two interesting use-cases of SWEEP are from the field of environmental research, where it was used for analysis of satellite imagery data to learn about the effects of climate change on remote Arctic lakes and wildflower communities in Mt. Rainier National Park.
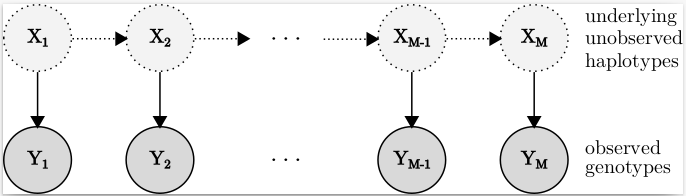
Efficient imputation of missing data with hidden-markov models on GPUs
Turns out the increasingly trendy GPU can be leveraged for old-school (non-deep) methods too. In this paper, we consider a computationally intensive HMM-based method for imputing missing data in genomes, and present an adaptation of the algorithm that reduces memory consumption enough to allow for execution on GPUs. We show that this pays off for the particularly challenging application of imputing ancient DNA, giving improved accuracy with similar runtimes compared to alternative pipelines.
GitHub
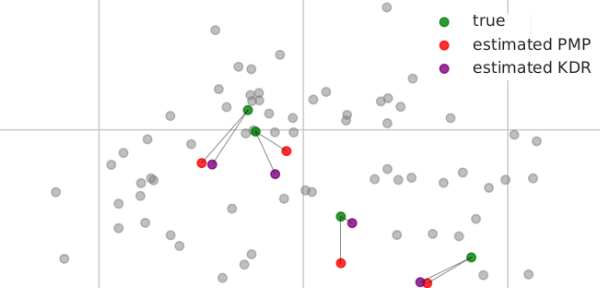
Handling missing data in PCA
Working with PCA in the field of population genetics, I often came across the problem of missing values in the data. I found that most implementations didn't have a lot of support for handling this (usually implementing the simplest solution of filling in missing values with 0), and that the issue wasn't discussed much overall.
I implemented some alternative methods that I found in the literature, had a go at using them on some data sets, and found that they gave much more accurate results (even the really simple and cheap ones).
I wrote this technical report about it. The Python source on GitHub is linked, and publishing a package is on my TODO list. Let me know if you're interested in using it.
GitHub
Massively parallel analysis of genome data
BAMSI: the BAM Search Infrastructure is a SaaS solution for cloud-based searching and filtering of massive genomic data sets. Based on celery and rabbitMQ, it can be used to set up multi-cloud, distributed processing of alignment files that leverages multiple mirrors of public data sets.
The framework is presented in this paper, where we also describe an implementation for the 1000 Genomes data set with a worker ecosystem spanning AWS and SNIC Science Cloud.
GitHub